倒排索引(Inverted Index)
倒排索引是实现“单词-文档矩阵”的一种具体存储形式,通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”。
原文:http://www.cnblogs.com/zlslch/p/6440114.html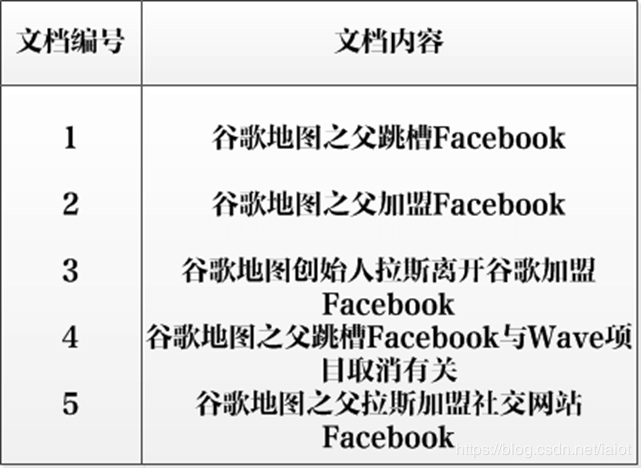
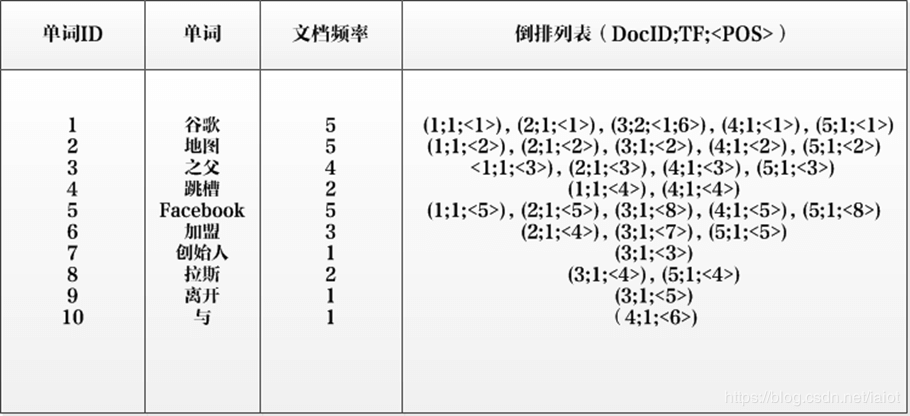
单词ID:记录每个单词的单词编号;
单词:对应的单词;
文档频率:代表文档集合中有多少个文档包含某个单词
倒排列表:包含单词ID及其他必要信息
DocId:单词出现的文档id
TF:单词在某个文档中出现的次数
POS:单词在文档中出现的位置
以单词“加盟”为例,其单词编号为6,文档频率为3,代表整个文档集合中有三个文档包含这个单词,对应的倒排列表为{(2;1;<4>),(3;1;<7>),(5;1;<5>)},含义是在文档2,3,5出现过这个单词,在每个文档的出现过1次,单词“加盟”在第一个文档的POS是4,即文档的第四个单词是“加盟”,其他的类似。
这个倒排索引已经是一个非常完备的索引系统,实际搜索系统的索引结构基本如此。
中文分词
https://github.com/medcl/elasticsearch-analysis-ik
http://www.cnblogs.com/zlslch/p/6440373.html
keyword 和 text
keyword:不进行分词,直接索引、支持模糊、精确查询、支持聚合
text:会分词,然后进行索引、支持模糊、精确查询、不支持聚合
默认的动态模板,可以同时支持两种类型
参考:https://elasticsearch.cn/question/2099
https://www.jianshu.com/p/0d13dd7d813a
https://blog.csdn.net/u011652364/article/details/78581737

